Disclaimer: I am not a historian. I am just a Computer Science educator who likes reading Wikipedia and printing funny characters. This explanation is a long optional appendix for a programming assignment in my course.
ASCII is the American Standard Code for Information Interchange. Developed starting in 1960, it was a way of standardizing means of communication between computers.
To explain, it’s useful to note that “8 bits” means two things from the perspective of a C++ programmer.
- These days all computers have standardized on organizing memory in bytes. That is to say, each memory address contains 8 bits.
- In C++, a char variable, representing a single character for communication, is also 8 bits wide.
Neither of these has been true forever. (Actually, some of the earliest computers did not use binary! But we’ll only be talking about bit-based computers here.)
- There were machines where each memory address contained some other number of bits like 22, 12, 18, 25, etc; see this table on Wikipedia.
- People used 5-bit Baudot codes for early communication. At 32 possible codes, that was just big enough for the English alphabet, but not lowercase letters or digits. This gradually expanded over the years to 6-bit, 7-bit and finally 8-bit codes.
However, 7 bits was sort of a sweet spot. At 128 possible codes, there was enough room for both lower-case and upper-case letters, digits, punctuation, with space left over for “control codes.” The development of ASCII in the 1960s was led by the American Standards Association. It proposed a standard meaning for all 128 values in a 7-bit code:
- The first 32 codes (0-31) were specific “control characters.” They didn’t have a direct graphical representation but instead had a specific semantic meaning. Notable examples are #0 the null character, #8 backspace, #9 tab, #10 line feed, and #13 carriage return.
- Character 32 was a space.
- Characters 33-126 meant the following, in order:
#33-63: !"#$%&'()*+,-./0123456789:;<=>
#64-95: @ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_
#96-126: `abcdefghijklmnopqrstuvwxyz{|}~
- Character 127 meant “delete”. Here is a quote from Wikipedia that gives a nice explanation:
This code was originally used to mark deleted characters on punched tape, since any character could be changed to all ones by punching holes everywhere. If a character was punched erroneously, punching out all seven bits caused this position to be ignored (or deleted).
Anyway, the idea of proposing ASCII as a way of standardizing was pretty good. It meant that if you had two machines communicating with each other, they had a chance to understand one another.
ASCII is ubiquitous now, but that was not always the case. Quoting this CNN article,
[T]here was an 18-year gap between the completion of ASCII in 1963 and its common acceptance. … Until 1981, when IBM finally used ASCII in its first PC, the only ASCII computer was the Univac 1050, released in 1964 (although Teletype immediately made all of its new typewriter-like machines work in ASCII).
The most well-known system not compatible with ASCII was EBCDIC. EBCDIC was developed in 1963. It is deeply weird in the sense that the letters of the alphabet don’t all contiguous codes. But there’s reason for this; it has to do with the Hollerith card code. Hollerith worked for the US Census and founded a startup in 1896 that was the precursor to IBM. The common punchcard standard that eventually dominated had 12 rows but not all 2048 combinations were viable, since it would destroy the card’s physical strength. So typical characters in a Hollerith code would punch up to 1 out of three “zone” rows plus up to 1 of out of nine “numeric” rows. Encode this as decimal and you get 36 choices from “00” to “39”. Then encode that as binary and all of a sudden you have a gap, e.g. formerly-adjacent codes 19 and 20 are all of a sudden 011001 and 100000. (This oversimplifies a bit, but a summary of the main point is that the BCD in EBCDIC means binary-coded decimal.)
 Also, EBCDIC did not contain all the punctuation characters that ASCII did. Some keyboards set up for EBCDIC did not have keys for characters like ^, { or }. See the 1972 international standard ISO 646, which is sort of a missing link between EBCDIC and ASCII. The presence of hardware and operating systems unable to support all characters is the reason that “C digraphs” and “C trigraphs” exist, e.g. that int x = 3 ??' 5 sets x equal to 4. (For applications of C di/trigraphs, see the IOCCC.)
Also, EBCDIC did not contain all the punctuation characters that ASCII did. Some keyboards set up for EBCDIC did not have keys for characters like ^, { or }. See the 1972 international standard ISO 646, which is sort of a missing link between EBCDIC and ASCII. The presence of hardware and operating systems unable to support all characters is the reason that “C digraphs” and “C trigraphs” exist, e.g. that int x = 3 ??' 5 sets x equal to 4. (For applications of C di/trigraphs, see the IOCCC.)
So in a nutshell EBCDIC existed due to the fact that hardware and software’s evolution was gradual and intertwined.
There’s another acronym that you’ll see a lot in researching this subject. Specifically, you’ll sometimes see ANSI as a synonym for ASCII, or to mean a variety of related concepts. What actually happened is that the American Standards Institute, which was the organization to develop ASCII, renamed itself the American National Standards Institute (ANSI) in 1969. From this ASCII gained another name retroactively, the “ANSI X3.4” standard. (And ANSI released more standards later on.)
Towards 8 bits
Eventually, ASCII was adopted more and more, which is why you don’t have an EBCDIC table in the appendix of your textbook. To this day, the word ASCII still technically refers to the 128-character 7-bit system mentioned above.
Over time, computer architectures did eventually standardize on word sizes and addressable locations that used bytes (8 bits). The PDP-8, sold commercially between 1963 and 1979, was the last popular machine whose word size was not a power of 2 (it used 12-bit words).
Hence, there was some wiggle room. A file on your hard drive, or a character being transmitted from computer to computer, or a char variable, actually had 8 bits of space, but ASCII only used 7. If you were to use all 8 bits, you could encode 256 possibilities, which was an extra 128 characters! This was particularly useful for non-English speakers, since most languages use accents or different letters not present in English. Spanish users would be interested in having ñ get one of those values in the unused space from #128-255, while French and Turkish speakers could use ç, Germans would like to add ß, Russians could use И, etc. But, there wasn’t enough space to satisfy everyone.
Enter the code page. This system, which became particularly common with DOS 3.3 in 1987, meant that every user could make their own choice about what system of letters would appear in those extra 128 slots. The most common English code page, CP 437, used those slots for the following characters:
#128-159: ÇüéâäàåçêëèïîìÄÅÉæÆôöòûùÿÖÜ¢£¥₧ƒ
#160-191: áíóúñѪº¿⌐¬½¼¡«»░▒▓│┤╡╢╖╕╣║╗╝╜╛┐
#192-223: └┴┬├─┼╞╟╚╔╩╦╠═╬╧╨╤╥╙╘╒╓╫╪┘┌█▄▌▐▀
#224-254: αßΓπΣσµτΦΘΩδ∞φε∩≡±≥≤⌠⌡÷≈°∙·√ⁿ²■
(The last character #255 is “non-breaking space,” another control character.)
Those lines and boxes were extremely useful in creating an entirely new domain, ASCII art. (Or maybe it is called ANSI art? Technically it should be called CP-437 Art but that name didn’t seem to take off.)
Of special mention is that on many machines of the DOS era, you could directly manipulate the screen’s contents. A program could set your monitor to text mode, for example 80×25 where there are 25 rows and 80 columns, each with room for a single letter. (Your VM looks like this when it boots up.) This is extremely similar to a bitmap: a 80-by-25 array of char values. In fact, the system assigned visual symbols or glyphs for all possible values from 0 to 255, even the non-printable control codes. So text-based games/art/applications of the day also had access to these symbols (in CP 437):

There were many other code pages. Almost all of them stuck to ASCII for the first 128 values (#0-127) and then added the 128 additional characters of local interest. E.g. here is what CP 866 contains at these positions:
#128-159: АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ
#160-191: абвгдежзийклмноп░▒▓│┤╡╢╖╕╣║╗╝╜╛┐
#192-223: └┴┬├─┼╞╟╚╔╩╦╠═╬╧╨╤╥╙╘╒╓╫╪┘┌█▄▌▐▀
#224-255: рстуфхцчшщъыьэюяЁёЄєЇїЎў°∙·√№¤■
The picture is further complicated by right-left languages and joined-letter scripts like Arabic, and languages like traditional Chinese with way more than 128 writing symbols.
In English communication, the Windows-1252 codepage became dominant. Compared to CP 437, it lost the line art, but gained smart quotes, fancy dashes, and other useful punctuation. (This made since because in Windows, they had real windows made out of pixels, rather than line art text mode graphics.)
For our Caesar Decipher assignment, the files will be given to you in the Windows-1252 format. (Technically, the internationally standardized Latin-1 subset.) But it shouldn’t matter, since your program will only do anything to those char values between ‘A’ and ‘z’, which are in the “official” ASCII range between 0 and 127.
Unicode
Most modern communications today, especially international ones, use a more recent system called Unicode.
One problem with the codepage system above is that you don’t really know what a file is saying just by looking at its bits. You can’t be sure if (char)161 means б, í, or something else. And there’s absolutely no way to represent a file that contains more than 256 distinct characters. (Such as this very article.)
This was eventually solved by Unicode, which began as an attempt to bring all of the code pages into a single system. Unicode is based on two principles:
- One unified and fixed numbering of all possible symbols. For example, б is 1073 (“CYRILLIC SMALL LETTER BE”) and í is 237 (“LATIN SMALL LETTER I WITH ACUTE”). Each possible symbol is called a unicode code point.
- A variety of different encodings, i.e. systems to encode a given sequence of code points as a series of bytes. (The most common encoding these days is UTF-8, a variable-width encoding.)
This system still had its growing pains and we’ll just mention the most noteworthy miscalculation. Joe Becker said in 1988,
Unicode aims in the first instance at the characters published in modern text (e.g. in the union of all newspapers and magazines printed in the world in 1988), whose number is undoubtedly far below 2^14 = 16,384. Beyond those modern-use characters, all others may be defined to be obsolete or rare; these are better candidates for private-use registration than for congesting the public list of generally useful Unicodes.
The Java language was even designed based on this assumption: a Java char is a 16-bit variable. However, this didn’t last long, and as of writing, the latest version of Unicode, version 7.0, contains 113,021 different characters (code points). In Java, this entailed the use of the UTF-16 encoding. In C++, you can read about the platform-dependent wchar type.
For historical context, you might read Kiss your ASCII Goodbye, written in 1992.
One thing is clear: at some point, maybe related to surpassing the 16,384-character limit, the Unicode consortium changed their definition of the “modern-use characters” that could fit in the standard. For example, character 9731 is ☃ (SNOWMAN). Try copying
http://☃.net
into your browser address bar.
 n Pursuit of The Travelling Salesman
n Pursuit of The Travelling Salesman![E[p^2(t+1)-p^2(t)|p^2(t)] = 1/2(p(t)+1)^2+1/2(p(t)-1)^2-p^2(t) = 1.](https://s0.wp.com/latex.php?latex=E%5Bp%5E2%28t%2B1%29-p%5E2%28t%29%7Cp%5E2%28t%29%5D+%3D+1%2F2%28p%28t%29%2B1%29%5E2%2B1%2F2%28p%28t%29-1%29%5E2-p%5E2%28t%29+%3D+1.&bg=ffffff&fg=333333&s=0&c=20201002)
![E[p(n)^2] = 1 + 1 + ... + 1 + 0 = n.](https://s0.wp.com/latex.php?latex=E%5Bp%28n%29%5E2%5D+%3D+1+%2B+1+%2B+...+%2B+1+%2B+0+%3D+n.&bg=ffffff&fg=333333&s=0&c=20201002)
![E[f(p(t+1))|p(t)] = f(p(t)).](https://s0.wp.com/latex.php?latex=E%5Bf%28p%28t%2B1%29%29%7Cp%28t%29%5D+%3D+f%28p%28t%29%29.&bg=ffffff&fg=333333&s=0&c=20201002)
![f(x) = f(p(0)) = E[f(p(end))] = Pr[win]*f(y) + Pr[lose]*f(0)](https://s0.wp.com/latex.php?latex=f%28x%29+%3D+f%28p%280%29%29+%3D+E%5Bf%28p%28end%29%29%5D+%3D+Pr%5Bwin%5D%2Af%28y%29+%2B+Pr%5Blose%5D%2Af%280%29&bg=ffffff&fg=333333&s=0&c=20201002)
![Pr[win] = (f(x)-f(0))/(f(y)-f(0)).](https://s0.wp.com/latex.php?latex=Pr%5Bwin%5D+%3D+%28f%28x%29-f%280%29%29%2F%28f%28y%29-f%280%29%29.&bg=ffffff&fg=333333&s=0&c=20201002)
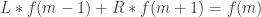 . Standard methods give all the solutions of this recurrence, almost any will do, but the simplest is to take
. Standard methods give all the solutions of this recurrence, almost any will do, but the simplest is to take 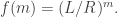 Then the probability of winning is
Then the probability of winning is